
This is the first of a two part engineering blog looking at data architecture for user behavioural data coming from a mobile application.

Part 1 (of 2): Challenges and architecture
For those of you who don’t know Bud, we are a technology provider that enables banks, and other financial service providers, to build money management apps on top of our APIs. For those of you who do know Bud, you may not know that we also have a Bud mobile app which is our testing and innovation vehicle to show off the platform capabilities. The Bud app helps us user-test new features, screens, flows, language… basically everything!
This user feedback is invaluable, but it's also a lot of data to collect and process, which presents some interesting technical challenges:
- Data is ingested 'live' at high volume and frequency
- We only get one chance to collect it. If you make a mistake on ingestion then it’s gone.
- We want to analyse it in real time, as this provides opportunity to interact with the user while they are online and helps us track engagement
- The data is inherently unstructured, i.e. different user actions will produce different information.
- We need to be cloud 'portable' i.e. we don't want to use any products or features that tie us into one cloud provider
- We need to be able to scale horizontally in a distributed environment
To address these challenges we built a streaming data architecture, which we’ll walk through in detail shortly, but first, let's start with some background. To get to market as quickly as possible in the early days of Bud, we stored this user behavioural data in a MySQL database which had a fixed schema. The variable part of the log message (see 4 above) was stored as a JSON blob in a separate field. This made data mining a little awkward, but worse it coupled our Mobile, Backend and Data teams together i.e. the Backend needed to know about the database schema and transform the logs coming in from Mobile to match. This doesn’t sound like a big deal until someone in Mobile wants to change the format of the log messages and suddenly you’ve got 3 co-ordinated releases on your hands to change the Mobile app, the Backend logic and the database schema in unison. All while running a 24/7 live app!
Step 1: Add a message queue
Our first aim was to disconnect the Backend from the database and prevent it accessing it directly. This gives us the first part of our architecture, the queue:
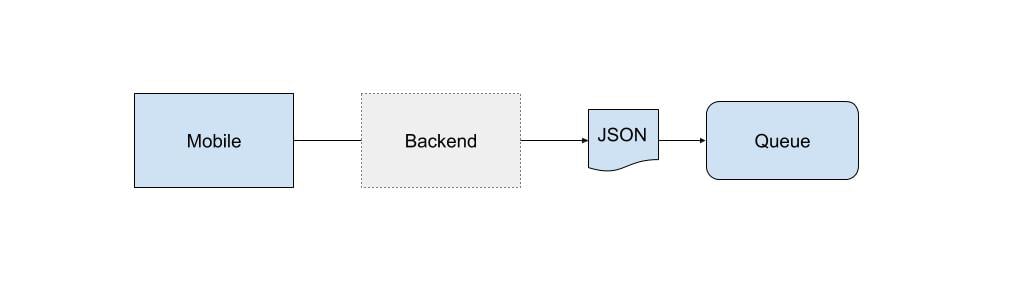
The queue doesn’t care about the content or structure of the JSON and the Backend can now simply pass through what it receives from Mobile making it schema agnostic. In the old world, a bug in the Backend logic, an outage or schema change on the database could cause data to be lost (thankfully that never happened!). We can also add a retention policy on the queue if there’s nothing on the other end to consume message from it. This makes our overall architecture more resilient.
Step 2: Create a data lake
All responsibilities beyond the queue now sit with the Data team, so what next? We need to process these messages and persist them. That gives us the second step, building a pipeline and data lake:
-1.jpg?width=1024&name=How%20were%20building%20a%20streaming%20architecture%20for%20limitless%20scale,%20Part%201_%20Apache%20Beam%20and%20being%20cloud%20agnostic%20(1)-1.jpg)
We want minimal logic in the pipeline so its sole responsibility is to persist the data. Just like with the Backend now becoming a pass-through, we’re minimising the number of things that could go wrong and also optimising performance. The data lake is our ‘single source of truth’, all the data in its raw form, which is important because we will want to transform it optimally for different use cases. The data lake is schemaless and massively horizontally scalable.
Step 3: Create an analytics database
The third step in the architecture focuses on mining the data and transforming it into a form we actually want to use for analytics:
.jpg?width=1024&name=How%20were%20building%20a%20streaming%20architecture%20for%20limitless%20scale,%20Part%201_%20Apache%20Beam%20and%20being%20cloud%20agnostic%20(2).jpg)
The first pipeline, as well as persisting to the data lake, relays the message to a secondary queue. Again this queue has retention built in, should something go wrong with its consuming pipeline and there’s no subscriber listening to its messages we won't drop them. The secondary pipeline can extract and transform data as required, it can even query the data lake if required (dotted line above) and insert it into a database optimised for reads and aggregations. This database is a columnar database and data will be inserted into tables with defined schemas. The number and schema of these tables can vary depending on what use cases we need by adding different logic to our secondary pipeline to perform the necessary ETL steps (extract, transform, load).
Previously we mentioned how we designed this architecture to be cloud 'portable' so that we aren’t tied to one cloud provider. Here’s a list of how it translates across different providers:
|
Component |
AWS | GCP |
|
Queue |
Amazon simple query service (SQS) | Google cloud pub/sub |
|
Pipeline |
Apache Beam | Apache Beam |
|
Data lake |
Amazon S3 | Google Cloud Storage |
|
Analytics Database |
Amazon Redshift | Google BigQuery |
There’s plenty of documentation on these various cloud products and our usage of them is fairly standard so I won’t go into those further here, but for the second part of this discussion, I’d like to talk more about how the architecture evolved and why we chose Apache Beam for building data streaming pipelines.



